
#
Advancing Confidential AI with Confidential Computing
#
Introduction
As artificial intelligence (AI) workloads increasingly handle sensitive data, ensuring their confidentiality and integrity is paramount. Phoeniqs, in collaboration with IBM Research, Red Hat, Intel, and Nvidia, has made significant strides in enabling confidential AI through the integration of AMD Secure Encrypted Virtualization-Secure Nested Paging (SEV-SNP) with OpenShift Sandboxed Containers (OSC). This blog explores the technical advancements and proof-of-concept (PoC) demonstrations made by Phoeniqs, in collaboration with IBM research, enriched by advancements from the Open-Source Confidential Containers (CoCo) project. The focus is on secure AI workflows and GPU-accelerated confidential containers for x86 bare-metal environments.
#
Understanding Confidential Containers
Confidential Containers (CoCo) leverage trusted execution environments (TEEs) to protect containerized workloads, isolating sensitive applications from the host operating system, other workloads, and the cloud provider. Key features include:
- Hardware-Based Security: Utilizes TEEs like AMD SEV-SNP, Intel TDX, and IBM Z Secure Execution Environment to protect the memory of the container.
- Attestation: Verifies the integrity of the execution environment.
- Secure Key Management: Integrates with key management systems (KMS) for secret provisioning.
- Open-Source Ecosystem: Built on Kubernetes and Kata Containers, supporting cloud-native workloads.
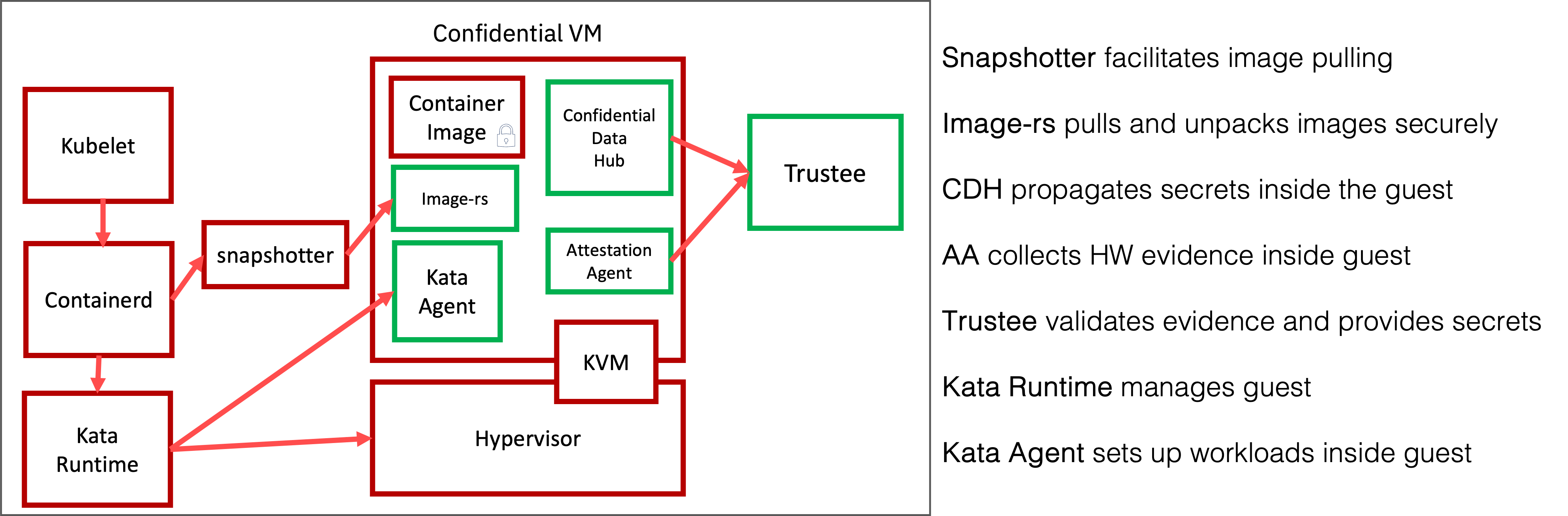
Figure 1: Confidential Containers Architecture with TEEs and Kubernetes
Our project and contributions align with CoCo’s goals, with specific focus on supporting AI workloads by integrating AMD SEV-SNP with OSC for secure, GPU-accelerated containers on x86 bare-metal systems.
#
Confidential AI Workflows
The Phoeniqs project envision the deployment of a large language model (LLM) in confidential containers against which applications will make secure requests followed by system-level operations. Adapted for confidential AI, it leverages encrypted models to protect sensitive data at rest, complementing CoCo’s secure execution principles.
#
Key Features of the Modified Workflow
- Encrypted Models: Safeguards models from unauthorized access.
- Scalability: Supports requests for large-scale AI tasks.
- System Integration: Manages attestation and resource allocation (System).
- CoCo Alignment: Ensures workloads run in a TEE-protected environment.
#
Proposed Confidential AI Workflow Architecture
To address the security requirements of confidential AI, IBM Research has proposed a robust architecture for protecting AI workflows, particularly for large language model (LLM) inference. This architecture ensures end-to-end protection across requestors, proxy, and inference engine, leveraging CoCo and confidential computing technologies.
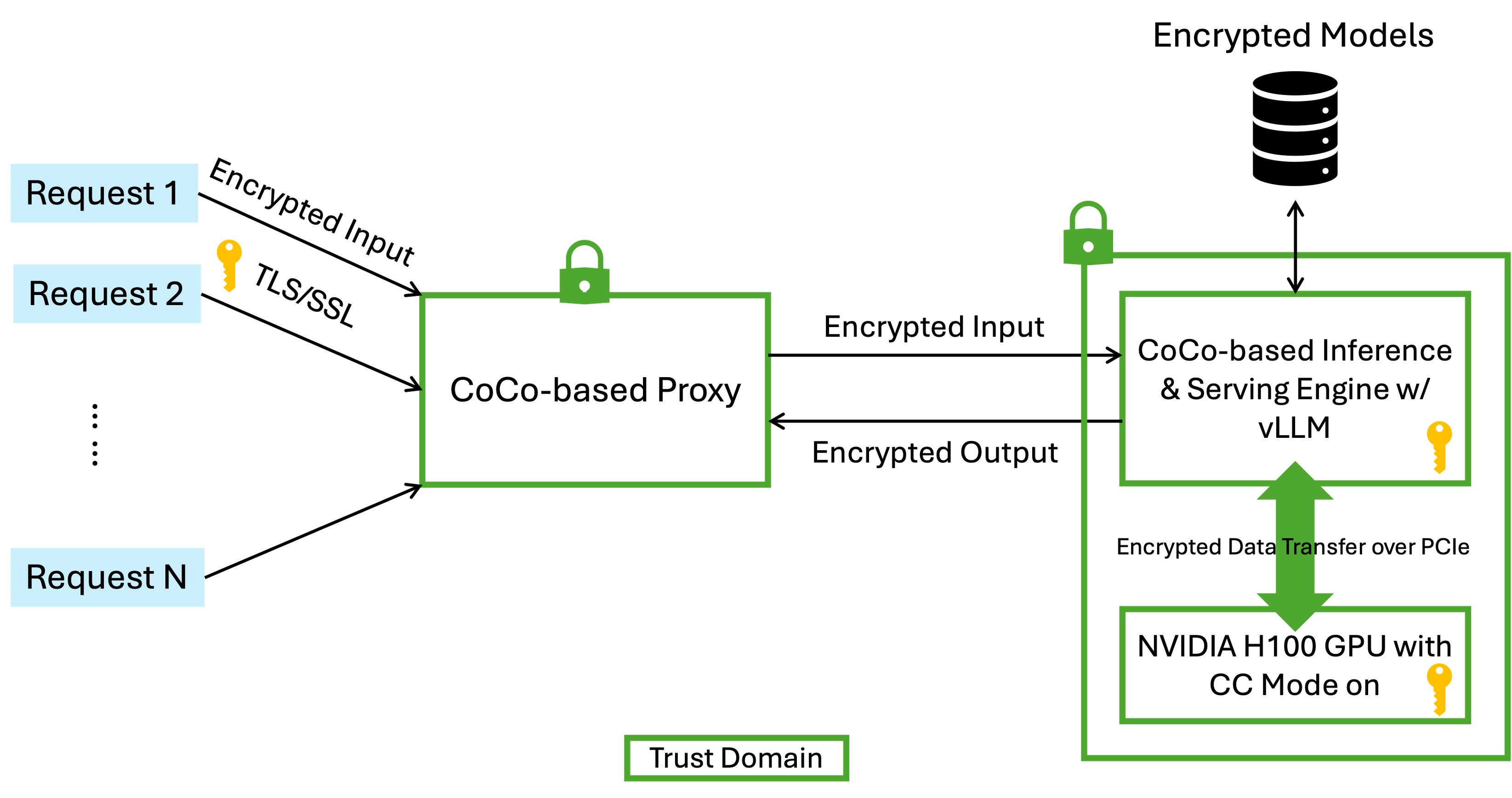
Figure 2: LLM Workflow For Confidential AI with Encrypted Models
#
Key Components and Security Measures
- Requestor-to-Proxy Communication:
- Protected using TLS/SSL to encrypt input and output tokens, preventing intermediaries from accessing plaintext data.
- Proxy POD:
- Runs in a Confidential Container POD, utilizing SEV-SNP to protect memory from infrastructure provider and from a compromised/untrusted OpenShift cluster.
- Inference Server POD:
- Operates in a Confidential Container POD with a GPU Confidential Mode on(e.g., Nvidia H100 PCIe), ensuring data in the GPU is inaccessible outside the POD.
- Data transferred between CPU and GPU over PCIe bus is encrypted, maintaining data confidentiality during computation.
- Proxy-to-Inference Server Communication:
- Secured using POD-to-POD transparent encryption, a feature IBM Research is developing and upstreaming to the CoCo project. This eliminates the need for container image modifications.
- Model Protection:
- Proprietary models are stored in an encrypted format and decrypted only within the vLLM POD, ensuring model confidentiality.
This architecture, while an example, encapsulates the core requirements for a confidential AI workflow and can be generalized to platforms like OpenShift AI or IBM Watsonx.ai. The Phoeniqsteam prioritizes the development of the Inference Engine POD due to its complexity, as detailed in subsequent sections.
#
Proof-Of-Concept - Run AI workloads in GPU-Accelerated Confidential Containers
With the help of IBM Research, Phoeniqs has customized an OpenShift installation to support the setup shown in the Figure 3.
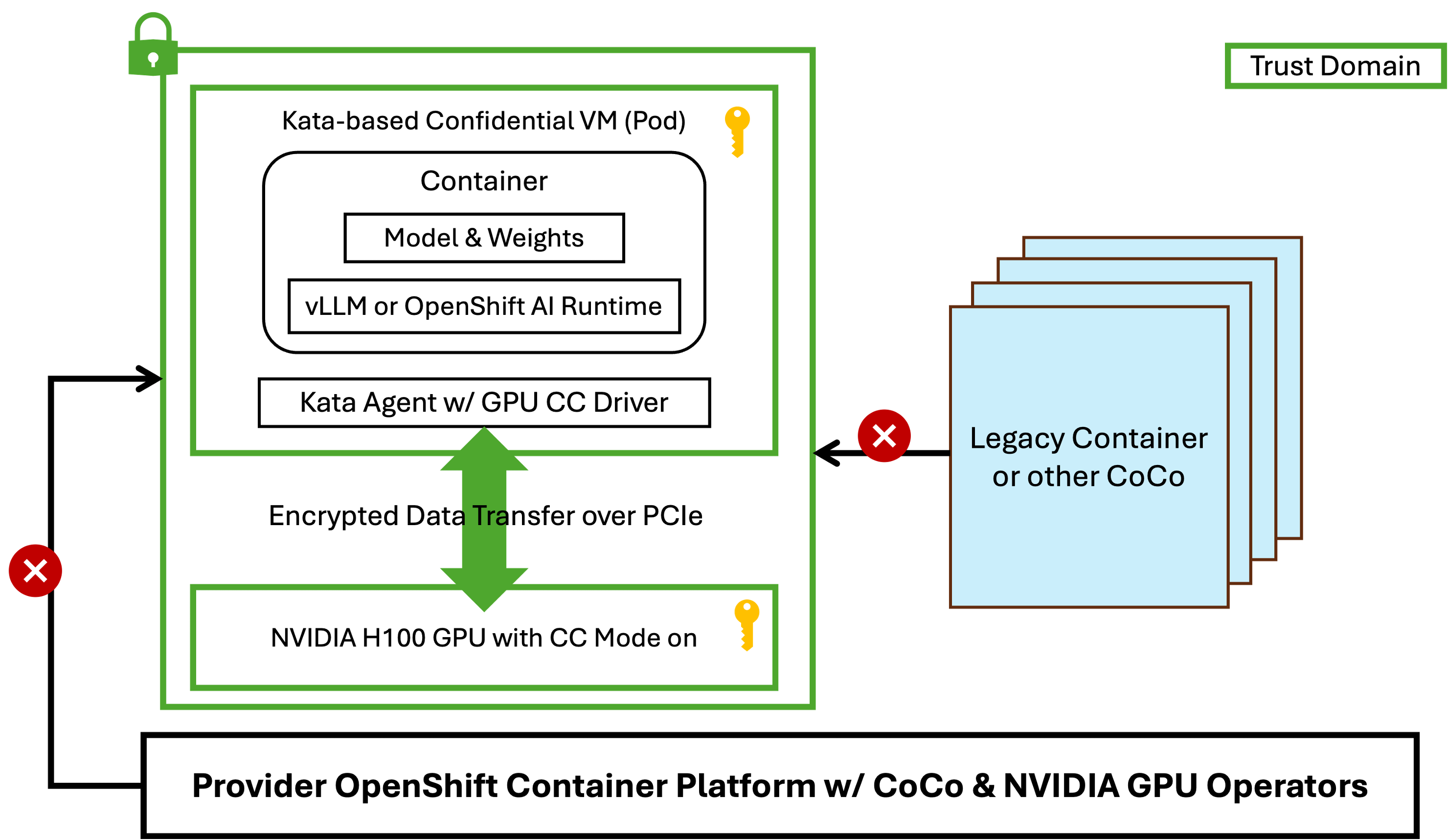
Figure 3: PoC Setup with Nvidia H100 GPU and AMD SEV-SNP
#
How to setup the Confidential AI envrironment
For the PoC, the following components were installed:
Hardware:
- AMD EPYC Genoa CPU.
- Nvidia H100 PCIe GPU.
Software:
Single-node OpenShift 4.16+ (OCP): Base platform for Kubernetes orchestration.
- Operators: Sandboxed Containers, Nvidia GPU Operator, Node Feature Discovery.
Bare-Metal CoCo Setup: Configured using install-helpers-0.1.0 scripts.
- NFD Operator: Deployed to manage node features.
- RHEL 9.5 Kernel Upgrade: Upgraded host kernel to support SEV-SNP.
- RHEL 9.5 Qemu: Installed to support SEV-SNP VMs.
- Kata Containers 3.16.0 Artifacts with tweaks: Included shim, configuration file, guest kernel, initrd with Kata Agent, RH Pause Image, CDH, Attestation Agent, and API Server for SEV-SNP pod VMs.
Runtime:
kata-snp-nvidia-gpuruntime class.- CRIO handler with
kata-qemu-nvidiagpu-confidentialartifacts.
The Phoeniqs PoC demonstrates a near future where GPU-accelerated confidential containers using Nvidia H100 PCIe GPUs in an SEV-SNP-enabled environment will be possible in OpenShift, directly supporting our vision of a confidential Inference Server POD. Our PoC is already able to run GPU-based workload and has been tested with a CUDA workload (vectorAdd) and a vLLM container image running inference with the Granite-3.0-2b model.
NOTE: AMD SEV-SNP Support in OpenShift Sandboxed Containers: AMD SEV-SNP provides hardware-based memory encryption and attestation for virtual machines (VMs). IBM and Red Hat have integrated AMD SEV-SNP into OSC, enabling confidential containers for secure AI workloads.
#
Attestation with Trustee
Attestation ensures container integrity. The PoC also integrates Trustee in a Secure Execution enclave via IBM’s Hyper Protect Virtual Server. By running Trustee in a Hyper Protect Virtual Server, we can provide a service that allows every client to easily run their attestation server in a secure, protected environment.
Confidential Trustee can attest a wide variety of confidential guests:
- Confidential VMs
- Confidential Containers
- AMD SEV-SNP and Intel TDX
Additionally, as part of this project, Phoeniqs and IBM Research are working in the Open-Source CoCo project to extend Trustee to provide attestation of confidential devices. Once this is upstream, we plan to leverage it in our deployment to allow the client to use a single tool (Trustee) to attest the TEE and the devices attached to it.
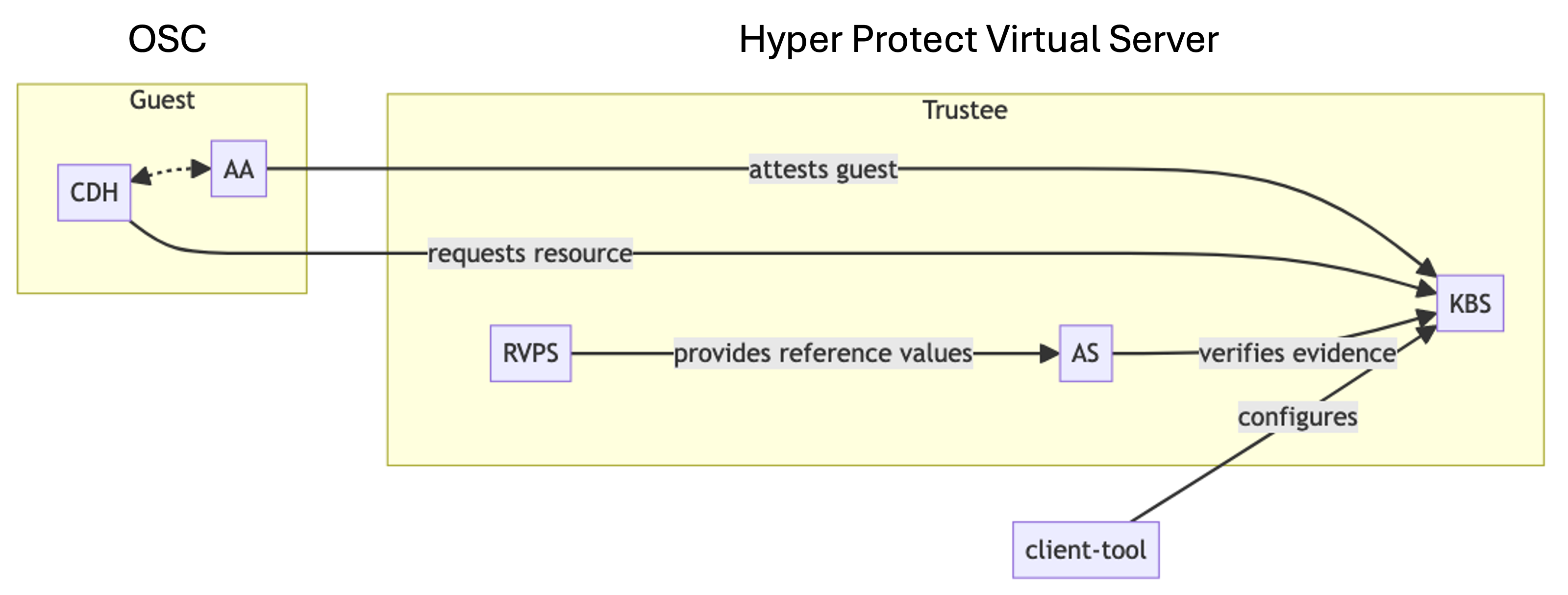
Figure 7: Trustee Attestation Process in CoCo
Features
- Broad Attestation Support: Confidential VMs and containers (AMD SEV-SNP, Intel TDX).
- Secure Communication: HTTPS and KBS attestation protocol.
- Secret Management: Integrates secrets from Trustee, HSM, or KMS.
- Ongoing Development: Attestation for confidential devices.
#
Creation of POD AMD SEV-SNP
The diagram below shows how we can create a Confidential POD in our PoC cluster.
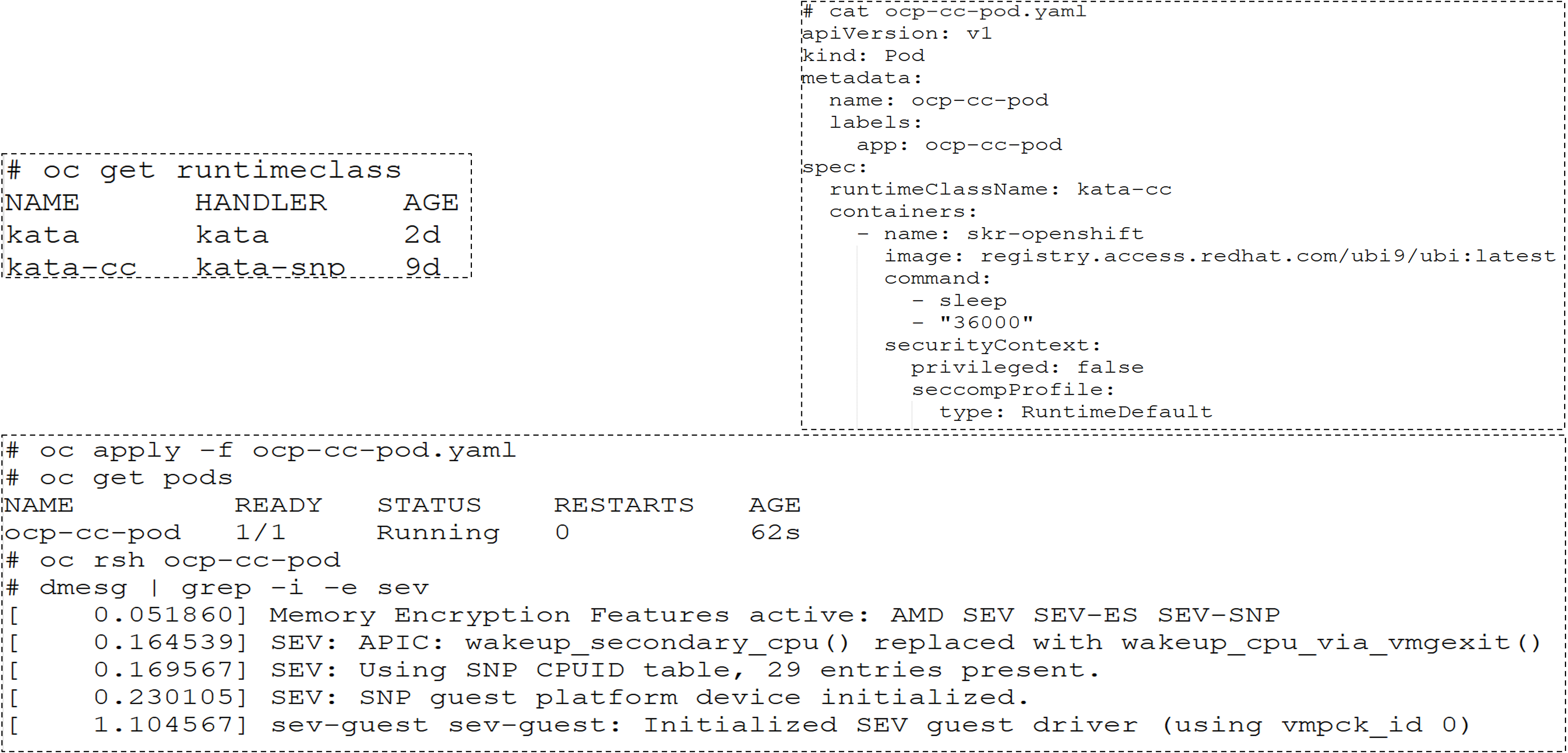
Figure 7: POD AMD SEV_SNP in CoCo
#
POD Manifest
Similarly, the diagram below shows the changes introduced in the POD Manifest to request an accelerator.
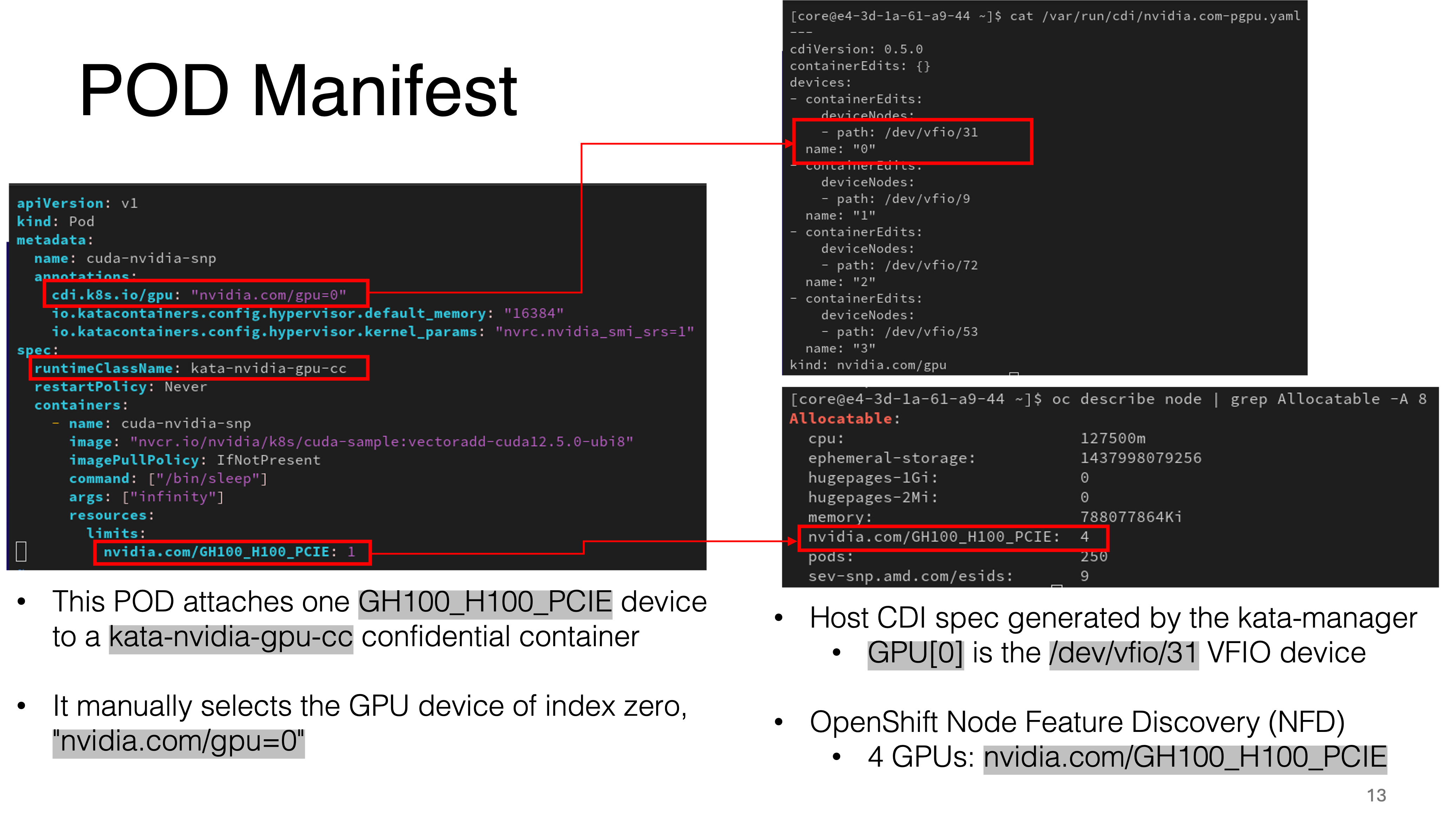
Figure 7: POD Manifest in CoCo
#
Sample Output
Finally, this shows that we can connect to the running POD and execute a GPU workload
oc exec -ti pod/cuda-nvidia-snp -- /bin/bash
[root@cuda-nvidia-snp /] # dmesg | grep -i sev
[ 1.400833] Memory Encryption Features active: AMD SEV SEV-ESP
[ 1.400837] SEV: Status: SEV SEV-ESP SEV-SNP
[ 9.666645] SEV: SNP guest platform device initialized.
[root@cuda-nvidia-snp /] # nvidia-smi conf-compute -f
CC status: ON
[root@cuda-nvidia-snp /] # nvidia-smi conf-compute -grs
Confidential Compute GPUs Ready state: ready
[root@cuda-nvidia-snp /] # /cuda-samples/vectorAdd
[Vector addition of 50000 elements]
Test PASSED
Done
#
CoCo’s Role in Enhancing Confidential AI
To summarize, CoCo provides a robust framework for Phoeniqs:
- Isolation: Kata Containers and TEEs ensure AI workload isolation.
- Cloud-Native Integration: Kubernetes enables seamless OpenShift deployment.
- Community Collaboration: Open-source model fosters innovation.
- Use Cases: Supports secure AI model training and inference.
#
Demonstrations and Impact
- Successful Runs:
- Nvidia CUDA samples (
vectorAdd). - vLLM with Granite-3.02b-base.
- Nvidia CUDA samples (
- Ongoing Work:
- OpenShift AI + vLLM demonstration.
- Blog Posts:
- Red Hat (January 20, February 19, 2025) on confidential containers.
#
Conclusion
The integration of AMD SEV-SNP with OSC, enhanced by CoCo and detailed in the RH Summit material, advances confidential AI on x86 bare-metal systems. Combining hardware security, GPU acceleration, and cloud-native architecture, IBM Research and partners enable secure AI workloads. The Phoeniqs PoC showcases complex AI tasks in secure environments, and CoCo’s ecosystem ensures scalability.
#
References
- Confidential Containers Project. (2025). Overview. Retrieved from Confidentail Containers - Overview
- Red Hat. (January 20, 2025). Introducing Confidential Containers on Bare Metal. Retrieved from Redhat - Confidential Containers on Bare Metal
- Red Hat Developer. (February 19, 2025). How to Deploy Confidential Containers on Bare Metal. Retrieved from Redhat Developer- Deploy Confidential Containers on Bare Metal
- Confidential Containers. Deploy Trustee in Kubernetes. Retrieved from Confidential Containers - Deploy Trustee in Kubernetes
- Documentation. Confidential Containers. Retrieved from Confidential Containers - Documentation
#
Special Thanks
The advancements in confidential AI with AMD SEV-SNP and OpenShift, as detailed in this blog, would not have been possible without the contributions of numerous individuals and teams. We express our gratitude to the following:
- IBM Research Team: For their collaboration with Phoeniqs, on confidential AI workflows, and driving the integration of Confidential GPUs with OpenShift Sandboxed Containers (OSC).
- Red Hat Team: For their collaboration on integrating AMD SEV-SNP into OSC, providing technical expertise, and contributing to the CoCo project, including the development of Kata Containers and the Trustee Operator.
- Confidential Containers (CoCo) Community: For their open-source efforts in standardizing confidential computing at the container level, particularly for upstreaming features like POD-to-POD transparent encryption.
These individuals and teams have been instrumental in pushing the boundaries of secure AI workloads, ensuring data confidentiality, and fostering innovation in the confidential computing landscape. Their dedication to collaboration, open-source development, and rigorous security practices has made the Phoeniqs PoC and related advancements possible. Thank you for your outstanding contributions!
#
Abbreviations
- AI: Artificial Intelligence
- SEV-SNP: Secure Encrypted Virtualization-Secure Nested Paging
- OSC: OpenShift Sandboxed Containers
- PoC: Proof-of-Concept
- CoCo: Confidential Containers
- LLM: Large Language Model
- TEE: Trusted Execution Environment
- KMS: Key Management System
- NFD: Node Feature Discovery
- GPU: Graphics Processing Unit
- CC: Confidential Compute
- SPDM: Security Protocol and Data Model
- TLS/SSL: Transport Layer Security/Secure Sockets Layer
- vLLM: Virtual Large Language Model
- RHEL: Red Hat Enterprise Linux
- Qemu: Quick Emulator
- KBS: Key Broker Service
- HSM: Hardware Security Module
- CDI: Container Device Interface
- VFIO: Virtual Function I/O